import matplotlib
if not hasattr(matplotlib.RcParams, "_get"):
matplotlib.RcParams._get = dict.get
Modul 2 Eftermiddag#
Introduktion til SVD#
Enhver reel \(m \times n\) matrix \(A\) kan skrives på SVD-formen
hvor \(V\) er en ortogonal \(n\times n\) matrix, \(\Sigma\) er en \(m \times n\) diagonal matrix, og \(U\) er en ortogonal \(m \times m\) matrix.
Elementerne i \(\Sigma\) kaldes singulærværdierne. De er alle større eller lig med \(0\) og står i ikke-stigende rækkefølge.
Nedenfor er et eksempel på en \(3\times 4\) matrix med singulærværdierne \(12\), \(6\) og \(0\), som er opskrevet på SVD-form:
I Python kan vi benytte SVD-kommandoen np.linalg.svd(A) for en \(m\times n\) matrix \(A\), når vi har importeret numpy (se under “Opsætning” nedenfor).
Matrix Approksimation#
Opsætning#
Vi importerer de nødvendige python-pakker.
# Biblioteker vi bruger
import numpy as np
from numpy.linalg import svd, matrix_rank
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap, BoundaryNorm
from matplotlib.image import imread
from PIL import Image
# Visninger
np.set_printoptions(precision=3, suppress=True)
plt.rcParams.update({'figure.max_open_warning': 0})
SVD kommando for en \(m\times n\) matrix \(A\)#
En \(m\times n\) matrix med tilfældige heltal mellem eksempelvis \(1\) og \(5\) som indgange kan laves med np.random.randint().
Vælg \(m\) og \(n\) og dan en tilfældigt generet matrix
m = 'INDSÆT KODE HER'
n = 'INDSÆT KODE HER'
np.random.seed(0) # fastlåser "tilfældigheden"
A = np.random.randint(1,6,size=(m,n))
A
SVD-kommandoen np.linalg.svd(A) for en matrix \(A\) giver (\(m\times m\))-matricen \(U\), \(\,\) (\(n\times n\))-matricen \(V^T\) og en vektor \(\boldsymbol{s}\) med singulærværdier i ikke-stigende orden.
Benyt SVD-kommandoen til at fremkalde \(U\), \(V^T\) og vektoren \(\boldsymbol{s}\) for matricen \(A\).
# Beregn SVD
U, s, Vt = 'INDSÆT KODE HER'
print('\nSingulærværdier (s):', s)
print('\nU =\n', U)
print('\nVt =\n', Vt)
Dan \(\Sigma\) matricen ud fra singulærværdierne i \(\boldsymbol{s}\) ved at færdiggøre koden nedenfor.
# Vi opretter en nulmatrix med samme dimensioner som A (m x n).
Sigma = np.zeros((m, n))
# Indæst de singulære værdier (s) på diagonalen.
for i in range(min(m, n)):
Sigma[i, i] = 'INDSÆT KODE HER'
print('\nSigma =\n', Sigma)
Vis at SVD-kommadoen passer ved at danne produktet \(U\Sigma V^T\).
# Husk at bruge @ til at lave matrixmultiplikation
recon = 'INDSÆT KODE HER'
print('\nRekonstruktion (U @ Sigma @ Vt) =\n', np.round(recon,3))
print('\nA =\n', A)
En rang-\(r\) matrix er en sum af \(r\) lineært uafhængige rang-\(1\) matricer#
Lad \(A\) være en \(m \times n\) matrix med rangen \(r \leq \min\{m,n\}\) og lad \(\boldsymbol{u_1}, \boldsymbol{u_2}, \dots, \boldsymbol{u_r}\) betegne de første \(r\) søjler i \(U\) og \(\boldsymbol{v_1}^T, \boldsymbol{v_2}^T, \dots, \boldsymbol{v_r}^T\) de første \(r\) rækker i \(V^T\).
Matricen \(A\) kan da opskrives som summen

For store matricer med lav rang er ovenstående en effektiv lagringsmetode med et minimalt forbrug af tal.
Vi indfører derfor udtrykket lagringstallet \(LA\).
Gør rede for at \(LA\) er givet ved
\[ LA(r,m,n) = \dfrac{r (1 + m + n)}{m n} \]
Kommentér kort, hvad der sker med lagringstallet, når \(r\) nærmer sig \(\min(m, n)\).
Vi ser på matricen
\(A\) har SVD-dekompositionen
Angiv rangen af \(A\) direkte ud fra SVD opstillingen.
Tjek dit svar ved at definere \(A\) ved at bruge kommandoen
np.array([], dtype=int)og benyt kommandoennp.linalg.matrix_rank()til at finde rangen.
# DEFINÉR A HER OG FIND RANGEN
Brug \(\boldsymbol{u_1}\), \(\boldsymbol{u_2}\) og \(\boldsymbol{u_3}\) samt \(\boldsymbol{v_1}^T\), \(\boldsymbol{v_2}^T\) og \(\boldsymbol{v_3}^T\) i nedenstående kodecelle til at eftervise \((*)\) i eksemplet.
Du kan benyttenp.outer()til at beregne \(\boldsymbol{u_i}\boldsymbol{v_i}^T\).
# Singularvektorer fra SVD (som tidligere vist)
u1 = np.array([1/2, 1/2, 1/2, 1/2])
u2 = np.array([1/2, -1/2, -1/2, 1/2])
u3 = np.array([1/2, -1/2, 1/2, -1/2])
v1T = np.array([2/3, -1/3, 2/3])
v2T = np.array([2/3, 2/3, -1/3])
v3T = np.array([-1/3, 2/3, 2/3])
# Singularværdier
sigma1, sigma2, sigma3 = 24, 12, 6
# Eftervis relationen (*)
A_reconstructed = 'INDSÆT KODE HER'
print("A rekonstrueret fra u1,u2,u3 og v1T,v2T,v3T:\n", A_reconstructed)
Funktionen nedenfor beregner lagringstallet \(LA\) givet \(r\), \(m\) og \(n\).
def Lagringstal(r,m,n):
return r*(1+m+n)/(m*n)
Bestem lagringstallet for \(A\) ved at benytte funktionen
Lagringstal.
# INDSÆT KODE HER
NB: For små matricer med høj rang er \((*)\) en dyr måde at lagre på!
Rang-\(k\) matrix approksimation og bevaret information#
Givet en \(m \times n\) matrix \(A\) med rangen \(r \leq \min\{m,n\}\) og lad \(k\) være et positivt helt tal med \(k \leq r\). En rang-\(k\) approksimation \(A_k\) af \(A\) fremkommer ved trunkering af den fulde SVD for \(A\), det vil sige, at man kun beholder de første \(k\) singulærværdier og tilsvarende singulærvektorer, mens de resterende singulærværdier sættes lig \(0\).
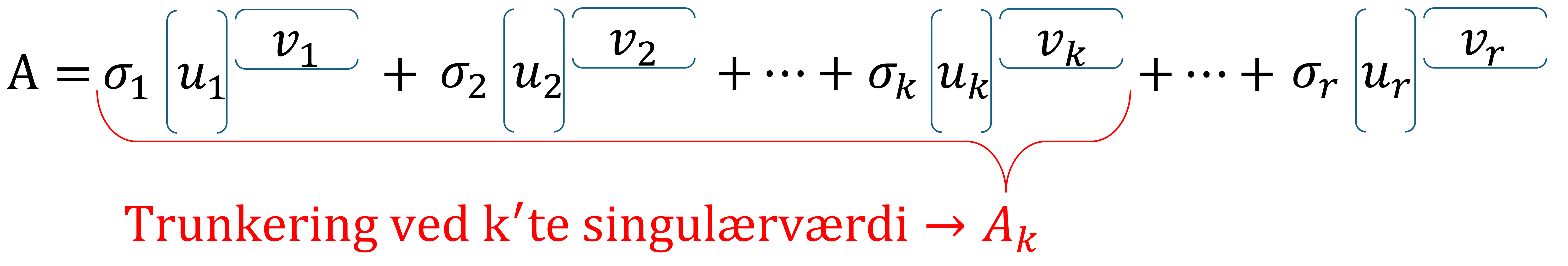
Dette kan matematisk skrives som:
Vi betrager igen matricen
Husk at \(A\) har SVD-dekompositionen
Bestem rang-\(1\), rang-\(2\) og rang-\(3\) approksimationerne \(A_1\), \(A_2\) og \(A_3\) ved hjælp af \((*)\) til nedenstående.
# Rang-1 approksimation
A1 = 'INDSÆT KODE HER'
# Rang-2 approksimation
A2 = 'INDSÆT KODE HER'
# Rang-3 approksimation
A3 = 'INDSÆT KODE HER'
# Udskriv resultaterne
print("Rang-1 approksimation A1:\n", A1)
print("\nRang-2 approksimation A2:\n", A2)
print("\nRang-3 approksimation A3:\n", A3)
Hvor stor er forskellen mellem \(A\) og dens approksimationer?
Definér \(A\) i kodecellen nedenfor og udregn \(A-A_1\), \(A-A_2\) og \(A-A_3\) og sammelign de tre resultater.
# INDSÆT KODE HER
Hvor meget information bevares ved approksimation?#
Det er klart, at jo flere singulærværdier man tager med, desto bedre bliver approksimationen. Man taler om, hvor meget information der bevares ved approksimationen.
Der findes flere måder at vurdere, hvor meget information man bevarer. Den formel, vi benytter her, afhænger kun af, hvor mange singulærværdier man tager med, som jo ved rang-\(k\) approksimation er \(k\) singulærværdier.
Den bevarede information \(BI\) ved rang-\(k\) approksimation af en \(m\times n\) matrix \(A\) med rank \(r\) er givet ved
hvor \(\sigma_1, \dots, \sigma_r\) er de ikke-negative singulærværdier af \(A\), og \(r = \text{rank}(A)\).
Bestem den bevarede information ved approksimationerne \(A_1\), \(A_2\) og \(A_3\) i vores eksempel.
# Rang af A
r = len(s)
# Bevaret information: k = 1,2,3
BI1 = 'INDSÆT KODE HER'
BI2 = 'INDSÆT KODE HER'
BI3 = 'INDSÆT KODE HER'
print("Bevarede information ved rang-1 approksimation:", np.round(BI1,3))
print("Bevarede information ved rang-2 approksimation:", np.round(BI2,3))
print("Bevarede information ved rang-3 approksimation:", np.round(BI3,3))
Opstilling af funktioner for større matricer#
For store matricer \(A\) får vi brug for funktioner (procedurer) til bestemmelse af approksimationerne \(A_k\), bevaret information \(BI\) og illustration af \(BI\).
Approksimationerne finder vi ved trunkering af summen \((*)\), hvor vi kun medtager de første \(k\) led.
Gennemgå koden for funktionen
svd_approksimation()i cellen nedenunder og indse at den ønskede approksimation \(A_k\) bestemmes.
def svd_approksimation(A, k):
"""
Rank-k SVD-approximation
"""
U, s, Vt = np.linalg.svd(A)
A_k = np.zeros_like(A, dtype=float) # nulmatrix med samme dimensioner som A
for i in range(k):
A_k += s[i] * np.outer(U[:, i], Vt[i, :]) # sum af ydreprodukter givet antal af medtagne singulærværdier
return A_k
Afprøv
svd_approksimation()på matricen \(A\) fra forrige afsnit for forskellige \(k\) og sammenlign resultaterne.
# INDSÆT KODE HER
Gennemgå koden for funktionen
bevarede_information()i cellen nedenunder og indse at den beregner \(BI\) for alle \(k\).
def bevarede_information(A):
"""
Bevarede information
"""
_, s, _ = np.linalg.svd(A) # vi skal kun bruge singulærværdierne
return np.cumsum(s / np.sum(s)) # np.cumsum giver den kumulative sum
Beregn \(BI\) for alle \(k\) ved at bruge funtionen
bevarede_information()på matricen \(A\).
# INDSÆT KODE HER
Gennemgå koden for funktionen
plot_bevarede_information()i cellen nedenunder og indse at den plotter den bevarede information som funktion af antallet af medtagne singulærværdier.
def plot_bevarede_information(A):
bevarede_info = bevarede_information(A) * 100 # i procent
# tilføj et 0 i starten så grafen starter i (0,0)
bevarede_info = np.insert(bevarede_info, 0, 0)
ks = np.arange(0, len(bevarede_info)) # array med antal singulærværdier
plt.plot(ks, bevarede_info, marker='o')
plt.xlabel("Antal singulærværdier (k)")
plt.ylabel("Bevarede information [%]")
plt.title("Bevarede information")
plt.grid(True, linestyle='--', alpha=0.6)
if len(bevarede_info) > 200:
plt.xticks(ks[::30])
else:
plt.xticks(ks)
plt.show()
Plot den beregnede information som funktion af antallet af medtange singulærværdier ved at bruge funktionen
plot_bevarede_information()på matricen \(A\).
# INDSÆT KODE HER
LEGO-skibet#
Vi tager udgangspunkt i et billede af et LEGO-skib fundet på internet.
Undervejs kommer vi til at:
Undersøge SVD og rang-\(k\) approksimation.
Implementere og visualisere \(k\)-rangs-rekonstruktion af billeder i Python.
Bruge SVD til billedkompression og tolke singulærværdier.
Vi betragter følgende billede fra internettet:

Modellering af LEGO-enheder#
Vi kan definere en LEGO-enhed som et lille rektangel, der indeholder to cylindre, set fra oven.
Det er nemt at se, at der er \(11\) enheder lodret.
Man kan også tælle, at der er \(15\) enheder vandret.
Nu skal vi vælge farver til 2D-rekonstruktionen af LEGO-figuren. Vi kan bruge et udvalg af farver fra CSS Colors: Matplotlib CSS Colors
Når hver LEGO-enhed og baggrunden får tildelt et tal svarende til dens farve, opstår der en \(15\times11\) matrix \(A\), som repræsenterer LEGO-figuren i 2D.
Vi antager, at du får brug for en farve til baggrund og ca. syv forskellige farver til LEGO-figuren.
Gå frem således:
I den følgende celle skal du i listen
base_colorserstattewhitemed de farver du har valgt. Derved tildeles farverne et tal fra \(1\) til \(8\), svarende til deres plads i listen. Den første farve du vælger, svarer til tallet \(1\), det vil sige baggrundsfarven.Derefter skal du i matricen \(A\) erstatte hver
xmed det tal, som du har valgt til LEGO-enheden, så enheden får den farve, som du ønsker.Når du er færdig, skal du køre cellen og de følgende celler for at se din LEGO-figur i 2D.
base_colors = ['white','white','white','white','white','white','white','white']
A = np.array([
[1,1,1,1,1,1,x,x,1,1,1,1,1,1,1],
[1,1,1,1,1,x,x,x,1,1,1,1,1,1,1],
[1,1,1,1,x,x,x,x,1,1,1,1,1,1,1],
[1,1,1,x,x,x,x,x,1,1,1,1,1,1,1],
[1,1,x,x,x,x,x,x,1,1,1,1,x,1,1],
[1,x,x,x,x,x,x,x,1,1,x,x,x,x,1],
[x,x,x,x,x,x,x,x,1,1,1,x,x,x,1],
[1,1,1,1,1,1,x,x,1,1,1,x,x,x,1],
[1,1,1,x,x,x,x,x,x,x,x,x,x,x,x],
[1,1,1,1,x,x,x,x,x,x,x,x,x,x,1],
[1,1,1,1,1,x,x,x,x,x,x,x,x,1,1]
], dtype=int)
Hint
Forslag til farvelægning.
# Knyt en farve til tallene + fejl-farver i hver ende
base_colors = ['palegreen','white','red','forestgreen','blue','yellow','black','cyan']
# Hver Lego-enhed tildeles et tal
A = np.array([
[1,1,1,1,1,1,3,3,1,1,1,1,1,1,1],
[1,1,1,1,1,4,4,4,1,1,1,1,1,1,1],
[1,1,1,1,3,3,3,3,1,1,1,1,1,1,1],
[1,1,1,4,4,4,4,4,1,1,1,1,1,1,1],
[1,1,3,3,3,3,3,3,1,1,1,1,2,1,1],
[1,4,4,4,4,4,4,4,1,1,7,7,7,7,1],
[3,3,3,3,3,3,3,3,1,1,1,8,8,6,1],
[1,1,1,1,1,1,5,5,1,1,1,6,6,6,1],
[1,1,1,2,2,2,2,2,2,2,2,2,2,2,2],
[1,1,1,1,2,2,2,2,2,2,2,2,2,2,1],
[1,1,1,1,1,2,2,2,2,2,2,2,2,1,1]
], dtype=int)
# KØR DENNE CELLE FOR AT SE DIN LEGO-FIGUR
extended_colors = ['magenta'] + base_colors + ['magenta']
cmap = ListedColormap(extended_colors)
# Definér grænser så værdier <0.5 og >8.5 bliver vist som magenta
bounds = np.arange(-0.5, len(extended_colors) - 0.5 + 1, 1)
norm = BoundaryNorm(bounds, cmap.N)
# 2) Figur og akse
fig, ax = plt.subplots(figsize=(6,5))
# 3) Tegn billedet – først billedet, så grid (så grid’en ligger øverst)
im = ax.imshow(A, cmap=cmap, norm=norm,
extent=[-0.5, A.shape[1]-0.5, -0.5, A.shape[0]-0.5])
# 4) Lav grid med meshgrid + plot
# x går fra -0.5 til 14.5 (15 kolonner), y fra -0.5 til 10.5 (11 rækker)
x = np.arange(-0.5, A.shape[1] + 0.5, 1)
y = np.arange(-0.5, A.shape[0] + 0.5, 1)
X, Y = np.meshgrid(x, y)
ax.plot(X, Y, color='lightgrey', linewidth=0.7) # vertikale
ax.plot(X.T, Y.T, color='lightgrey', linewidth=0.7) # horisontale
# 5) Fjern ticks, sæt ensartet aspect, og giv en sort ramme
ax.set_xticks([]); ax.set_yticks([])
ax.set_aspect('equal')
# 6) Titel og show
ax.set_title("Originalt billede af LEGO skib")
plt.tight_layout()
plt.show()
Rang-\(k\) matrix approksimation#
For at komprimere vores LEGO-billede kan vi bruge SVD på matricen \(A\):
U, s, Vt = np.linalg.svd(A.astype(float))
Ved at plotte singulærværdierne får vi et klart indtryk af, hvor meget hvert enkelt led i summen i \((*)\) bidrager til den samlede matrix.
# Plot singulærværdier
plt.figure(figsize=(8,5))
plt.scatter(np.arange(1, len(s)+1), s, color='blue')
plt.title("Singulærværdiers størrelse for A")
plt.xlabel("Index")
plt.ylabel("Singulærværdi størrelse")
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
De største singulærværdier repræsenterer de mest betydningsfulde mønstre i LEGO-billedet, mens de små bidrager med mindre detaljer. Plottet hjælper os derfor med at beslutte, hvor mange singulærværdier vi kan beholde, uden at miste for meget information, hvilket er centralt, når vi laver en \(k\)-rang-approksimation af billedet.
Vi ønsker at visualisere det originale LEGO-billede og rang-\(k\) SVD-approksimationen side om side for at se effekten af approksimationen.
Færdiggør funktionen
plot_svd(k)ved at indsætte funktionensvd_approksimation()fra tidligere.
def plot_svd(k):
# Beregn k-rangs approksimation af A (kaldes A_recon)
A_recon = 'INDSÆT KODE HER'
fig, axes = plt.subplots(1, 2, figsize=(12, 5), dpi=100)
# Lav koordinatarrays til pcolormesh - definerer kanterne på hver pixel
x_edges = np.arange(-0.5, A.shape[1] + 0.5, 1)
y_edges = np.arange(-0.5, A.shape[0] + 0.5, 1)
# Lav meshgrid for kanterne
X, Y = np.meshgrid(x_edges, y_edges)
# Approksimation
ax = axes[0]
# Brug pcolormesh som naturligt aligner med griddet
mesh = ax.pcolormesh(X, Y, A_recon, cmap=cmap, norm=norm, shading='flat')
# Tilføj gridlinjer præcist på kanterne
ax.vlines(x_edges, y_edges[0], y_edges[-1], colors='lightgrey', linewidth=0.7)
ax.hlines(y_edges, x_edges[0], x_edges[-1], colors='lightgrey', linewidth=0.7)
ax.set_xlim(x_edges[0], x_edges[-1])
ax.set_ylim(y_edges[0], y_edges[-1])
ax.invert_yaxis() # Retter op-ned vendt billede
ax.set_aspect('equal')
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(f"Approksimation med k={k} singulærværdier")
# Originalt
ax = axes[1]
mesh = ax.pcolormesh(X, Y, A, cmap=cmap, norm=norm, shading='flat')
ax.vlines(x_edges, y_edges[0], y_edges[-1], colors='lightgrey', linewidth=0.7)
ax.hlines(y_edges, x_edges[0], x_edges[-1], colors='lightgrey', linewidth=0.7)
ax.set_xlim(x_edges[0], x_edges[-1])
ax.set_ylim(y_edges[0], y_edges[-1])
ax.invert_yaxis() # Retter op-ned vendt billede
ax.set_aspect('equal')
ax.set_xticks([])
ax.set_yticks([])
ax.set_title("Originalt billede")
plt.tight_layout()
plt.show()
Prøv forskellige værdier af \(k\) med funktionen
plot_svd(k)og se, hvordan billedet rekonstrueres. Hvilken effekt har det på billedets kvalitet?
# INDSÆT KODE HER
Prøv at rekonstruere matrixen ved at medtage alle singulærværdier. Hvorfor ser det præcis ud som det originale LEGO-billede?
Nedenfor undersøger vi, hvordan den bevarede information vokser med \(k\) ved at bruge funktionen plot_bevarede_information() fra tidligere:
plot_bevarede_information(A)
Hvor mange singulærværdier skal medtages for at opnå kumulativ forklaring på over \(90 \%\)?
Hvor stort bliver lagringstallet \(L(k,m,n)\) for den valgte \(k\)?
Hvordan hænger den bevarede information sammen med kvaliteten af billedet, når du ændrer antallet af medtagne singulærværdier?
Medbragt Billede#
Pixelværdier i billeder#
Et billede består af tal - hver pixel-værdi fortæller, hvor lys eller mørk den pixel er. I gråtonebilleder bruger man typisk heltal i området \(0–255\):
\(0\) = sort.
\(255\) = hvid.
Værdier imellem = gråtoner.
Til beregninger normaliserer man ofte til intervallet \([0, 1]\) ved at dividere med \(255\). For farvebilleder gemmes tre sådanne værdier per pixel (R, G, B), svarende til én rød, én grøn og én blå komponent.
Import af billede og databehandling#
I denne opgave kræver det, at du kan bruge dit eget foto. Derfor skal du på arbejde JupyterLite-siden https://intermat20.compute.dtu.dk/jupyterlite/index.html, hvor du kan uploade dit eget foto ved blot at “drag-and-droppe”.
Når du har uploadet dit billede til JupyterLite-siden, skal du ændre
INDSÆT FILNAVN HERtil filnavnet på dit billede.
Vi skal i opgaven arbejde med gråtone billeder, og derfor ændres dit billede til grayscale.
def load_image_matrix(path, max_dim=1000, to_gray=True):
"""
Indlæs et billede som et 2D (gråtoner) eller 3D (RGB) NumPy array i [0,1],
nedskaleret så det største mål højst er max_dim, med bevaret aspektforhold.
"""
im = Image.open(path) # Åbn billedfil (JPG/PNG mv.)
if to_gray:
im = im.convert("L") # Konverter til gråtoner
else:
im = im.convert("RGB") # Sørg for 3 farvekanaler (dropper evt. alfa-kanal)
w, h = im.size
scale = min(1.0, max_dim / max(w, h)) # Beregn skaleringsfaktor
if scale < 1.0:
# Skaler billedet ned hvis det er større end max_dim
new_size = (max(1, int(round(w * scale))), max(1, int(round(h * scale))))
im = im.resize(new_size, Image.LANCZOS)
# Konverter til NumPy-array med værdier mellem 0 og 1
arr = np.asarray(im, dtype=np.float64)
arr = arr / 255.0
return arr
# Indlæs billedet
A = load_image_matrix("INDSÆT FILNAVN HER", max_dim=512, to_gray=True) # INDSÆT KODE HER
plt.imshow(A)
plt.axis("off") # Skjul akser
plt.show()
Cellen nedenfor printer en dataoversigt for billedet.
# Dataoversigt for billedet
print('Objekt type:\n',type(A))
print('Dimensioner:\n',A.shape)
print('Datatype af elementer:\n',A.dtype)
print('Datainterval:\n',[np.min(A), np.max(A)])
Kør cellen ovenfor og overvej dimensionerne. Giver de mening?
SVD på billede#
Med den korrekte matrixrepræsentation af billedet, kan vi nu undersøge matricens rang.
print("Rangen af matrix:\n", np.linalg.matrix_rank(A))
Hvor mange ikke-nul singulær værdier kan vi forvente?
Vi udfører SVD på billedet:
U, s, Vt = np.linalg.svd(A)
Sigma = np.diag(s) # diagonalmatrix med s som diagonalindgange
Vis størrelsen af singulærværdierne i et plot.
# INDSÆT KODE HER
Hvad betyder det, at den første singulærværdi ofte er meget større end de næste?
Ligesom i øvelsen med LEGO-skibet vil vi nu undersøge singulærværdierne ud fra den bevarede information. Se plottet nedenfor.
plot_bevarede_information(A)
Aflæs på plottet hvad antallet af singulærværdier skal være for at opnå henholdsvis \(90 \%\), \(95 \%\) og \(99 \%\) af den bevarede information.
Konstruktion af approksimerede billeder#
Vi ønsker at konstruere approksimeringer af det originale sort-hvid billede, ved kun at bruge de første \(k\) singulærværdier.
Vi vil undersøge kvaliteten af approksimationerne, når der anvendes et forskelligt antal singulærværdier.
Benyt funktionen
svd_approksimation()til at færdiggøre funktionenplot_approksimation()nedenfor.
Funktionen plotter \(k\)-rangs-approksimationen og det originale billede side om side.
def plot_approksimation(A,k):
# Rang-k rekonstruktion via ydre produkter
A_recon = 'INDSÆT KODE HER'
# Figur med to plots
fig, axes = plt.subplots(1, 2, figsize=(10,5))
# Approksimation
ax = axes[0]
ax.imshow(A_recon, cmap='gray', interpolation='nearest')
ax.set_title(f'Rank-{k} approksimation)')
ax.set_xticks([]); ax.set_yticks([])
# Original
ax = axes[1]
ax.imshow(A, cmap='gray', interpolation='nearest')
ax.set_title('Original')
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.show()
Eksperimentér med antallet af singulærværdier og brug funktionen plot_approksimation(A,k) for at svare på følgende:
Hvor mange singulærværdier skal bruges, før motivet kan genkendes?
Hvor mange skal bruges, før man kan se detaljer?
Hvor mange skal bruges, før approksimationen er lige så god som det originale billede med det blotte øje.
Hvad svarer det til i bevarede information \(BI\) og lagringstal \(LA(k,m,n)\)?
Kan man genkende elementer i billedet i approksimationen, hvis kun den første singulær værdi bruges? Fx. himmel/land, baggrund/forgrund, og så videre.
Udfordrende: Farveapproksimation med SVD#
I de tidligere øvelser har vi kun arbejdet med gråtoner eller 2D LEGO-matricer. Rigtige billeder består typisk af tre farvekanaler: Rød (R), Grøn (G) og Blå (B). Hver kanal kan behandles som en matrix, hvor vi kan udføre SVD og lave en \(k\)-rangs-approksimation.
Ved at gøre dette for alle tre kanaler individuelt og sætte dem sammen igen, kan vi lave en komprimeret version af farvebilledet. Dette viser tydeligt, hvordan SVD kan bruges til billedkompression i farver. Vores procedurer svd_approksimation(), bevarede_information() og plot_bevarede_information() skal derfor udvides for at kunne håndtere 3 kanaler.
Opgaven er derfor:
Opdel dit medbragte billede i R, G og B kanaler.
Udfør SVD på hver kanal.
Lav rang-\(k\)-approksimation for hver kanal.
Sæt kanalerne sammen igen for at genskabe billedet.
Visualiser resultatet.
def svd_rgb_approksimation(img, k, verbose=False):
"""
Returnerer en k-rangs SVD-approksimation af et RGB-billede.
Parametre:
- img: et RGB-billede som numpy array (højde x bredde x 3)
- k: antal singulærværdier at medtage pr. kanal
Returnerer:
- img_recon: det approksimerede billede
"""
img = np.asarray(img)
# Konverter billedet til float med samme størrelse
imgf = img.astype(float)
# Lav en kopi af billedet, som vi kan fylde med approksimationen - brug np.zeros_like
img_recon = 'INDSÆT KODE HER'
# Gå gennem de tre farvekanaler (R, G, B)
for i in range(3):
# Beregn k-rangs approksimation for denne kanal - brug svd_approksimation(channel, k)
channel = imgf[:, :, i]
Xk = 'INDSÆT KODE HER'
img_recon[:, :, i] = Xk
# Sørg for, at pixelværdierne ligger inden for 0–1 - brug np.clip
img_recon = 'INDSÆT KODE HER'
return img_recon
A = load_image_matrix("INDSÆT KODE HER", max_dim=512, to_gray=False)
img_recon = svd_rgb_approksimation(A, k=100, verbose=True)
# Visualiser resultatet
plt.figure(figsize=(6,5))
plt.imshow(img_recon)
plt.title("RGB-rang-k approksimation")
plt.axis('off')
plt.show()
Vi ønsker at undersøge, hvordan den bevarede information udvikler sig for hver af de tre farvekanaler i et RGB-billede. Dette giver indsigt i, hvilke kanaler der bærer mest information, og hvor meget \(k\)-rangs approksimation kan komprimere billedet uden stort tab af kvalitet.
Udfør for hver kanal (Rød, Grøn, Blå) SVD.
Beregn den tilhørende bevarede information for hver kanal.
Plot resultaterne sammen og vurdér, hvor mange singulærværdier, der skal bruges, for at opnå \(90 \%\) af den bevarede information i hver kanal.
# Plot kumulativ varians forklaret for RGB-billedet med kanal-specifik farve
kanaler = ['Rød', 'Grøn', 'Blå']
farver = ['red', 'green', 'blue']
plt.figure(figsize=(8,5))
for i, (kanal, farve) in enumerate(zip(kanaler, farver)):
# Udfør SVD på hver kanal
'INDSÆT KODE HER'
# Beregn tilhørende kumulative information
'INDSÆT KODE HER'
# Plot kumulativ information
'INDSÆT KODE HER'
plt.xlabel('Antal singulærværdier medtaget')
plt.ylabel('Bevarede information')
plt.title('Bevarede information pr. farvekanal')
plt.axhline(0.9, color='black', linestyle=':', label='90% linje')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()